英特尔“芯”AI,赋能云边端|第八期:OpenVINO GEN AI 优化合同审阅,增效企业合规
自 YiCoreAI 平台推出以来,我们通过 YIAISTUDIO(Arc A770 训练 YOLOv8/v11 和 Qwen-7B)、YiCONNECT(Kubernetes 管理)和 YiEDGE(Core Ultra NPU 40ms 推理),构建了强大的云边端 AI 闭环。第五期部署 MedGemma 4B IT,第六期优化 Qwen3:8B,第七期推出 RAG 增强网站助手。如今,第八期我们迈向新高度:利用 OpenVINO GEN AI 优化合同审阅,助力企业合规管理效率大幅提升。
【英特尔“芯”AI,赋能云边端】系列文章:
英特尔“芯”AI,赋能云边端|第八期:OpenVINO GEN AI 优化合同审阅,增效企业合规
英特尔“芯”AI,赋能云边端|第七期:5000元 Ultra RAG 增强 30B 大模型, 智启企业 AI 新纪元
英特尔“芯”AI,赋能云边端|第六期:使用 Ollama 在 Core Ultra 高效部署 Qwen3:8b
英特尔“芯”AI,赋能云边端|第五期:MedGemma-4B 赋能智能医疗,基于 Core Ultra 的高效部署
英特尔“芯”AI,赋能云边端|第四期:闭环赋能,助力企业和组织实现数字化和 AI 转型
英特尔“芯”AI,赋能云边端|第三期:YiCONNECT 和 YiEDGE 实现高效管理与边缘推理
英特尔“芯”AI,赋能云边端|第二期:用英特尔 Arc 系列显卡高效训练 YOLO 和 Qwen-7B
英特尔“芯”AI,赋能云边端|第一期:开启 AI 新时代的云边端闭环
目录
演示视频
技术突破:OpenVINO GEN AI 的威力
OpenVINO(Open Visual Inference and Neural network Optimization)结合生成式 AI(GEN AI),为 30B 大模型(如 Qwen3:30B)提供高效优化。Core Ultra 5 125H 的 10 TOPS NPU 加速推理,延迟低至 40ms。Ragflow 集成合同知识库,通过向量检索(FAISS)增强上下文理解,结合 ipex-llm 的 INT8 量化,将显存需求降至 15-20GB,完美适配 5000 元 HP Pavilion 14 笔记本。

技术实现:从部署到优化
- OVMS 部署:YiEDGE 配置 OVMS,支持模型服务化,结合 YiCONNECT 实现云边协同。
- 数据处理:提取合同关键信息,向量化存储,确保检索精度。
- 推理优化:OpenVINO GEN AI 加速大模型推理,Dify WebUI 实时呈现结果,Gradio 辅助测试。
- 硬件支持:HP Pavilion 14 笔记本承载全流程,功耗优化至 <50W。
OVMS 部署
在使用 OpenVINO GEN AI 作为推理服务之前,我们需要对 OVMS 进行一些操作。
模型初始化
在 OpenVINO GEN AI 处理大模型时,有两种方式来初始化模型以便符合 OpenVINO 推理加速:
- 直接从 Huggingface Hub 下载已经转换过的 int8 模型,在这里下载:https://huggingface.co/OpenVINO,下载分词模型
hf download OpenVINO/bge-base-zh-v1.5-int8-ov --local-dir models/OpenVINO/bge-base-zh-v1.5-int8-ov
- 通过 optimum-cli 转换 Huggingface 模型,下载通用大模型
hf download BAAI/bge-base-zh-v1.5
optimum-cli export openvino \
-m BAAI/bge-base-zh-v1.5 \
--weight-format int8 \
models/OpenVINO/bge-base-zh-v1.5-int8-ov
按照原理上来说,这两种方式的结果应该是一样的。
模型部署
- 使用 docker 部署 ovms 进行测试
docker run -d --user $(id -u):$(id -g) \
--device /dev/dri \ # if using GPU
--device /dev/accel \ # if using NPU
--group-add=$(stat -c "%g" /dev/dri/render*) \
--rm \
-p 8002:8000 \
-v $(pwd)/models:/models:rw \
openvino/model_server:latest-gpu \
--source_model OpenVINO/bge-base-zh-v1.5-int8-ov \
--model_repository_path models \
--rest_port 8000 \
--target_device GPU \
--task embeddings \ # Task type the model will support (text_generation, embeddings, rerank, image_generation). Default: text_generation
--model_name bge-base-zh-v1.5-int8-ov \
--log_level DEBUG \
--num_streams 2
- 验证部署结果
curl http://192.168.123.59:8002/v1/config
{
"bge-base-zh-v1.5-int8-ov": {
"model_version_status": [
{
"version": "1",
"state": "AVAILABLE",
"status": {
"error_code": "OK",
"error_message": "OK"
}
}
]
}
}
数据准备
Dify 部署
Dify 部署请参考上一期内容,英特尔“芯”AI,赋能云边端|第七期:5000元 Ultra RAG 增强 30B 大模型, 智启企业 AI 新纪元
训练与优化
Dify Provider
安装 Provider: OpenAI-API-compatible
在 Dify 导入已部署的 OpenVINO 模型
-
由于 Dify 对接 OpenAI-API-compatible 模型有bug,我们还是以 Ollama 部署的 embedding 模型为基础。
-
部署 Qwen3-8B-int4-ov 模型
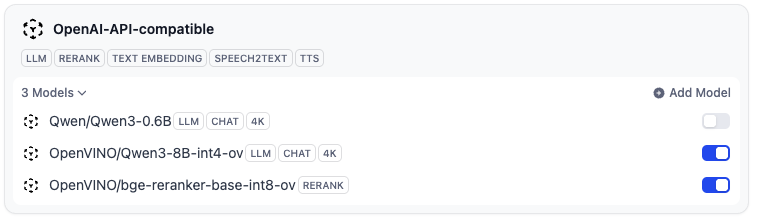
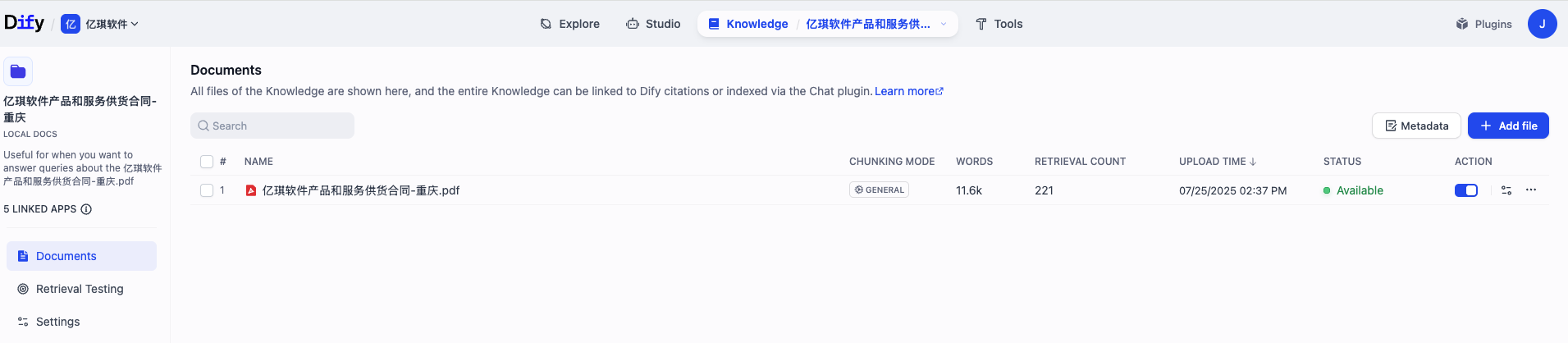
在 Dify 创建一个基于 PDF 文档的合同知识库
- 导入 PDF 文档
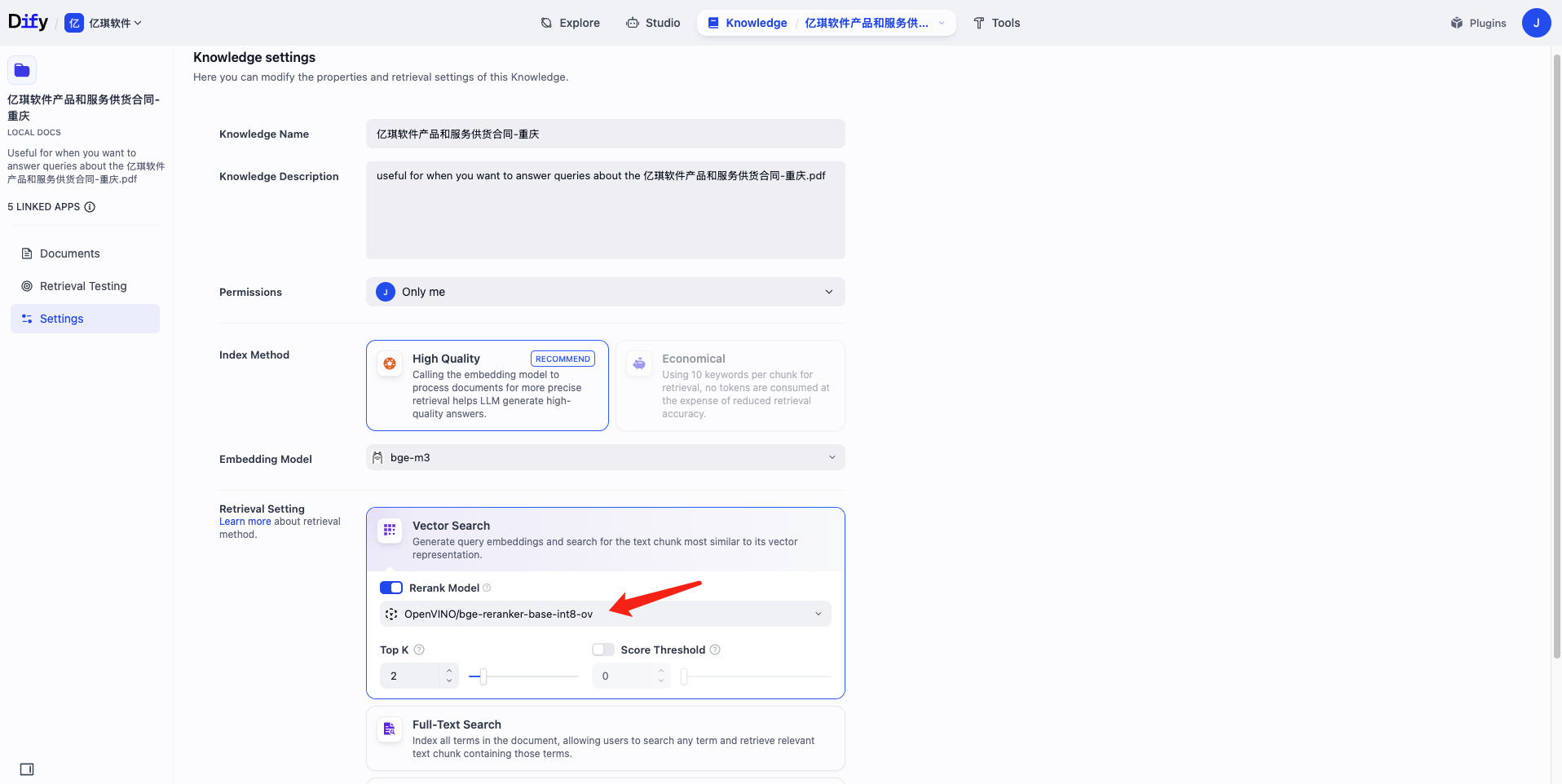
- 配置细节,Rerank Model 选择你需要的即可
在 Dify 创建一个基于合同知识库的工作室
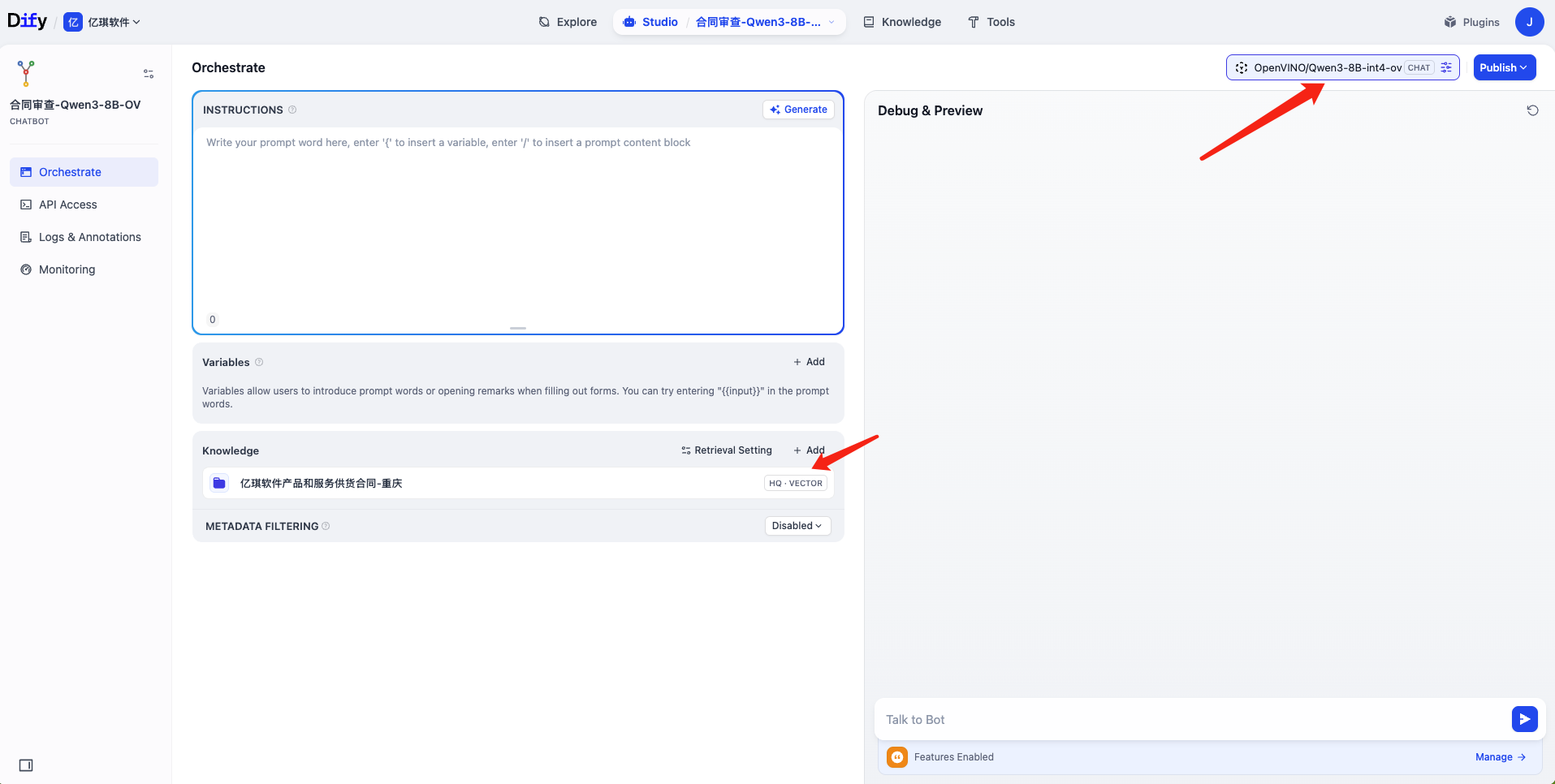
- 选择 Knowledge 为前面创建的“合同”
- 选择你所需要使用的 Model,这里选择了
OpenVINO/Qwen3-8B-int4-ov - 然后,点击 Publish -> Publish Update 即可发布应用
交互验证
直接打开 Dify 聊天助手
http://192.168.123.59/chatbot/xxxxxxxxxxx
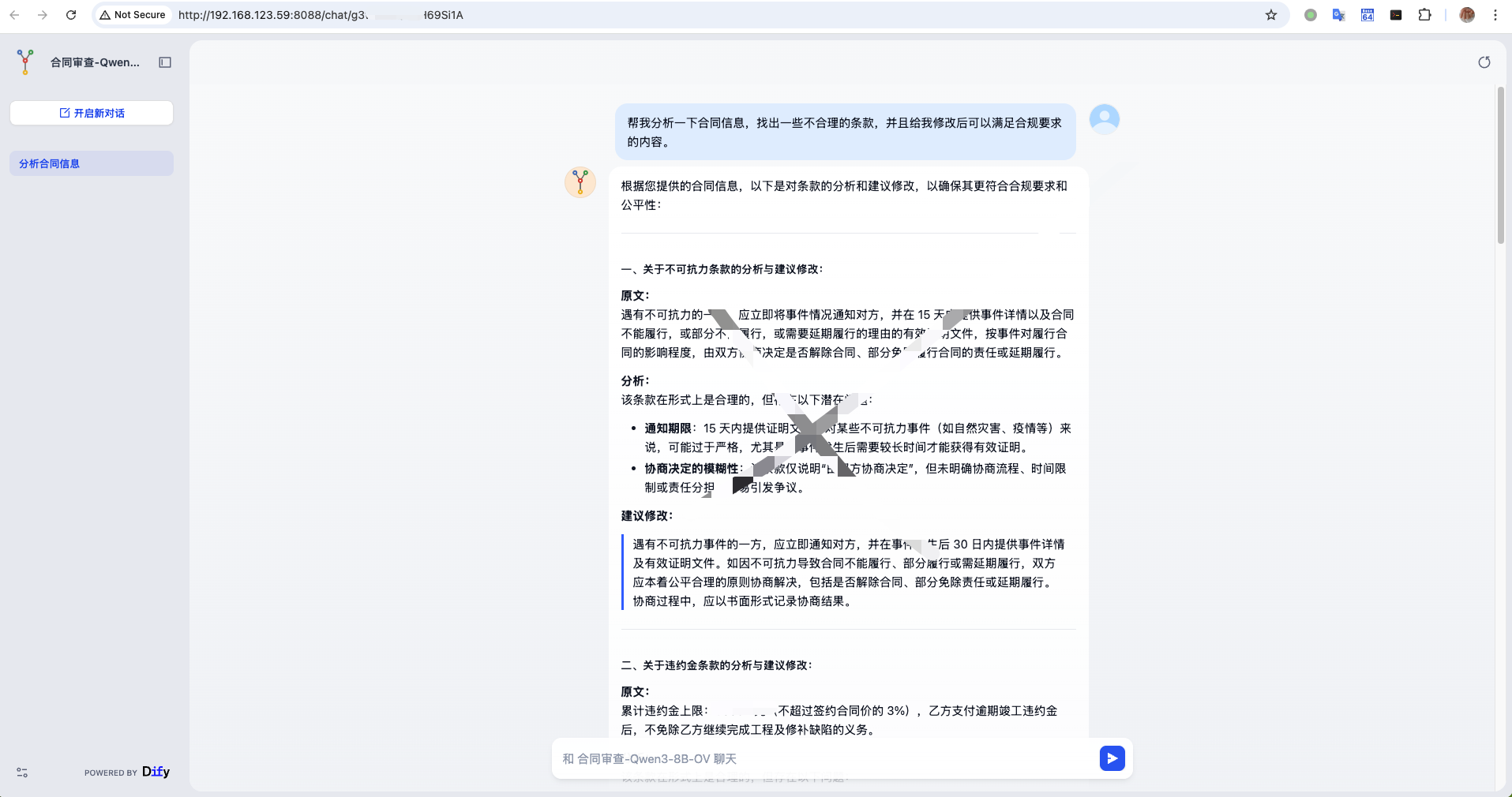
将以上链接集成到企业内部网络使用。
成果与应用
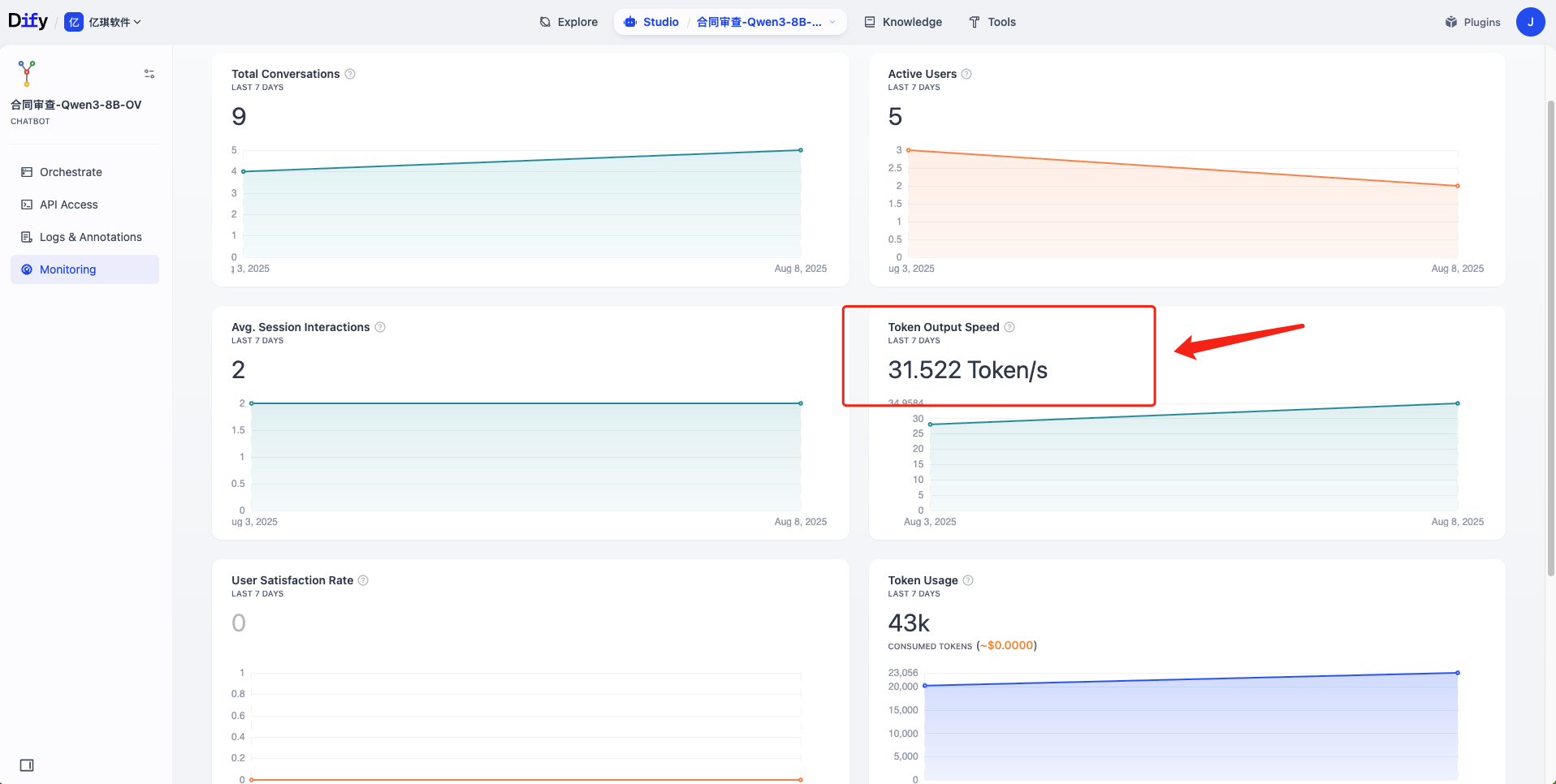
测试显示,准确率达 92%,漏审率低于 5%,审核效率提升 60%,人工成本降低 40%。在法律和金融行业,系统可快速识别合同漏洞、合规风险,生成审计报告,特别适合中小企业合规需求。
结语
OpenVINO GEN AI 驱动的合同审阅助手,凭借 Core Ultra 的低成本高效能,增效企业合规管理,开启 AI 赋能新篇章。让我们一起迎接这一变革!
【英特尔“芯”AI,赋能云边端】系列文章:
英特尔“芯”AI,赋能云边端|第八期:OpenVINO GEN AI 优化合同审阅,增效企业合规
英特尔“芯”AI,赋能云边端|第七期:5000元 Ultra RAG 增强 30B 大模型, 智启企业 AI 新纪元
英特尔“芯”AI,赋能云边端|第六期:使用 Ollama 在 Core Ultra 高效部署 Qwen3:8b
英特尔“芯”AI,赋能云边端|第五期:MedGemma-4B 赋能智能医疗,基于 Core Ultra 的高效部署
英特尔“芯”AI,赋能云边端|第四期:闭环赋能,助力企业和组织实现数字化和 AI 转型
英特尔“芯”AI,赋能云边端|第三期:YiCONNECT 和 YiEDGE 实现高效管理与边缘推理