方案|100% 开源边缘智能引擎:OpenVINO 与 EdgeX Foundry 完美结合,零代码即插即用实践(GitHub开源)
在边缘计算的浪潮中,人工智能(AI)推理从云端向边缘设备的迁移已成为趋势,带来更低的延迟、更高的隐私保护和更优的资源效率。Intel 的 OpenVINO™ 工具包及其 Model Server (OVMS),结合 EdgeX Foundry 的开源框架,提供了一个强大的边缘智能引擎。我们公司自豪地贡献了 GitHub 开源仓库 edgexfoundry-holding/device-ai-openvino-ovms,展示如何通过零代码、即插即用的方式,在 Intel CPU、GPU 和 NPU 上实现高效边缘 AI 推理。这一仓库是我们对开源社区的承诺,旨在推动边缘智能的广泛应用。
技术分享|The Next Generation Internet of Things 下一代物联网 曾经描述过:远端和物联网智能设备:遥远的、偏远的或网络资源匮乏的地方将是边缘计算的用武之地,不仅是减少了数据传输的时间和效率问题,还解决了现场智能设备的数据处理问题。
OpenVINO 简介:赋能边缘智能的强大工具
OpenVINO™(Open Visual Inference and Neural Network Optimization)是 Intel 推出的一款开源 AI 推理和优化工具包,旨在加速深度学习模型在边缘设备上的部署。它通过优化神经网络,支持多种模型格式(如 TensorFlow、ONNX、PyTorch 等),并针对 Intel 硬件(CPU、GPU、NPU)提供高效推理。OpenVINO 的核心组件包括模型优化器(Model Optimizer)和推理引擎(Inference Engine),能够显著降低计算复杂性,提升性能,同时保持精度。无论是工业 IoT、智能监控还是自动驾驶,OpenVINO 都为边缘 AI 提供了灵活、高效的解决方案。

OpenVINO Model Server:边缘推理的开源引擎
OpenVINO Model Server (OVMS) 是 Intel 开发的一款开源推理服务器,专为在 Intel 硬件上优化 AI 模型部署而设计。它通过 gRPC 和 REST API 接口,简化客户端与模型的交互,支持高效推理。
OVMS 的核心优势包括:
- 高性能优化:基于 OpenVINO Runtime,支持连续批处理和性能监控,最大化硬件加速。
- 多硬件支持:无缝适配 Intel CPU、GPU 和 NPU,满足异构计算需求。
- 灵活扩展:支持集群部署、模型仓库管理和动态配置,适应高负载场景。
- 开源兼容:支持 TensorFlow、ONNX 等多种模型格式,易于集成到生产环境。

OVMS 的 Docker 容器化部署使其特别适合边缘场景,用户无需修改代码即可实现低延迟推理,堪称边缘智能的理想引擎。
EdgeX Foundry:开源边缘计算的完美框架
EdgeX Foundry 是 Linux Foundation 下的开源 IoT 平台,采用微服务架构,提供硬件和 OS 中立的边缘计算解决方案。它包括核心服务(数据管理、命令控制)、设备服务(连接传感器)以及应用服务(与云端集成)。EdgeX 的模块化设计支持多种协议,并可通过自定义设备服务集成 AI 功能。
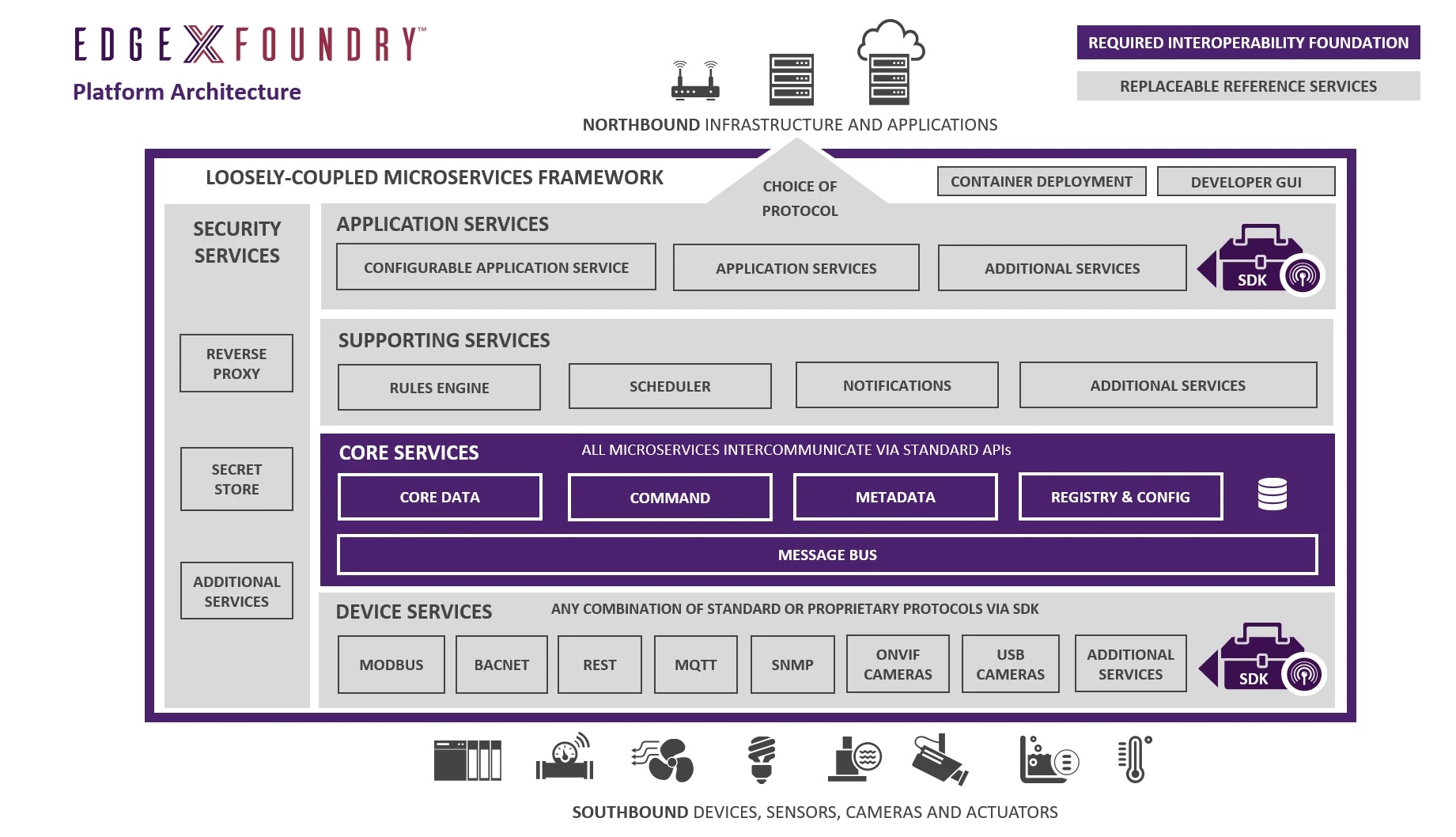
作为 EdgeX Leadership Global 成员,我们公司贡献的 device-ai-openvino-ovms 仓库,通过设备服务将 OVMS 集成到 EdgeX 中,支持物体检测模型(如 ssdlite_mobilenet_v2)。这一结合让边缘设备不仅能采集数据,还能实时执行 AI 推理,完美实现智能边缘。
仓库核心:零代码、即插即用的边缘 AI 实践
我们公司开发的这个开源仓库提供了一个 EdgeX 设备服务 demo,展示了如何利用 OVMS 实现边缘 AI 推理。
其亮点包括:
- 全硬件适配:支持 Intel CPU(默认)、GPU(需 --privileged Docker)和 NPU,覆盖多种推理场景。
- 灵活部署:模型服务器可运行在本地或远程主机,通过协议配置无缝切换。
- 实时结果:提供 MJPEG 流(如 http://localhost:18080/Simple-OpenVINO-Device.mjpeg)展示推理输出。
- 零代码体验:用户只需配置模型文件和 Docker 容器,无需编写代码即可部署。
快速上手步骤
- 安装依赖:安装 EdgeX Foundry、OpenVINO、OVMS 和 Gocv(Go 的 OpenCV 绑定)。
- 准备模型:将模型文件(如 ssdlite_mobilenet_v2 的 XML/BIN)放入指定目录。
-
启动 OVMS:运行 Docker 容器,指定硬件(如 CPU 或 GPU)。示例命令(CPU 模式):
GPU 模式需添加docker run -d -u $(id -u) --rm \ -v ${PWD}/model:/model \ -p 9000:9000 -p 8000:8000 \ openvino/model_server:latest \ # openvino/model_server:latest_gpu \ # 支持 CPU/GPU/NPU --model_name ssd \ --model_path /model \ --port 9000 \ --rest_port 8000 \ --metrics_enable # 开启 Metrics endpoint--privileged和/dev/dri挂载。 -
构建并运行:执行
make build && make run,启动设备服务。

仓库还提供推理结果示例(图像、GIF、视频),直观展示物体检测效果,体现了我们公司在边缘 AI 领域的技术实力。
集成 Prometheus 和 Grafana:实时监控边缘 AI 性能
为了确保边缘 AI 推理的可靠性和性能,我们的仓库集成了 Prometheus 和 Grafana,用于监控 OVMS 和 EdgeX 系统的运行状态。Prometheus 是一个强大的开源监控系统,能够收集和存储时间序列数据,而 Grafana 提供直观的可视化仪表板,帮助用户实时分析性能指标。
在仓库中,OVMS 暴露的指标(如推理延迟、吞吐量、硬件利用率)可通过 Prometheus 采集。例如,OVMS 提供了 /metrics 端点,支持监控请求处理时间和模型加载状态。用户可以配置 Prometheus 抓取这些指标,并通过 Grafana 创建自定义仪表板,展示 CPU/GPU/NPU 的使用情况、推理性能和系统健康状态。这种集成确保了边缘设备在高负载场景下的稳定性,特别适合工业场景下的持续运行。
配置 Prometheus 和 Grafana
-
启动 Prometheus:在 Docker 容器中运行 Prometheus,配置 prometheus.yml 以抓取 OVMS 的 /metrics 端点:
scrape_configs: - job_name: 'ovms' static_configs: - targets: ['<ovms_host>:8000'] -
启动 Grafana:部署 Grafana 容器,连接到 Prometheus 数据源,创建仪表板以可视化推理性能。
- 监控指标:关注关键指标,如 ovms_requests_total(请求总数)、ovms_inference_time_ms(推理延迟)和硬件资源使用率。

通过 Prometheus 和 Grafana,用户可以轻松跟踪边缘 AI 系统的性能瓶颈,确保高效运行。
为什么选择我们贡献的开源解决方案?
- 开源生态:基于 Apache-2.0 许可,依托 EdgeX 和 OpenVINO 的强大社区支持,我们的贡献进一步丰富了生态。
- 高效性能:OVMS 充分利用 Intel 硬件(尤其是 NPU),降低功耗,提升推理速度。
- 零代码部署:通过我们预配置的容器和模型,开发者无需编程即可实现 AI 推理,适合工业 IoT、智能监控等场景。
- 完美结合:我们将 EdgeX 的模块化架构与 OVMS 的推理能力无缝集成,扩展性强,体现了我们在边缘计算领域的创新。
相比云端推理,这一方案减少了网络依赖,提升实时性和数据隐私。例如,在智能零售中,边缘设备可直接进行人流检测,无需上传敏感数据。
结语
我们公司贡献的 edgexfoundry-holding/device-ai-openvino-ovms 仓库,结合 OpenVINO Model Server 和 EdgeX Foundry,打造了一个开源、零代码、即插即用的边缘智能引擎。在 Intel CPU、GPU 和 NPU 的支持下,开发者可以轻松构建高效的边缘 AI 应用。立即克隆仓库,体验我们团队为开源社区带来的这一实践方案,探索边缘智能的无限可能!